Six months ago, while running the engineering side of my consulting practice, I made a quieter version of a controversial decision: I would let coding agents write the bulk of my product work. Every PR that hit my repos would be drafted by Codex first, then reviewed by me before it landed.
To make that work, I redesigned my workflow from the ground up. I built agent-friendly repos, invested heavily in automated checks and CI, and treated Codex like a teammate rather than a power tool. The Conductor Mac app gave me a multi-workspace view to keep all of it organized, and for a while that was enough.
And it worked, but then I ran into the next bottleneck: context switching.
To solve that problem, I rebuilt my workflow around a system called Symphony. Symphony, open-sourced by OpenAI in April, is an agent orchestrator that turns a project-management board into a control plane for coding agents. Every open task gets an agent, agents run continuously, and humans review the results. My version sits on top of my own board, but the shape is the same as theirs.
This post explains how I moved from Codex plus Conductor to Symphony, resulting in roughly five times more landed PRs across my consulting work, and how the same shape of pattern can turn a normal issue tracker into an always-on agent factory.
The ceiling of interactive coding agents
Even as they get easier to use, coding agents, whether accessed through a web app, a Mac multi-workspace manager, or a plain CLI, are still interactive tools. Someone has to start the session, prime the prompt, watch the output, and decide what to do with the result.
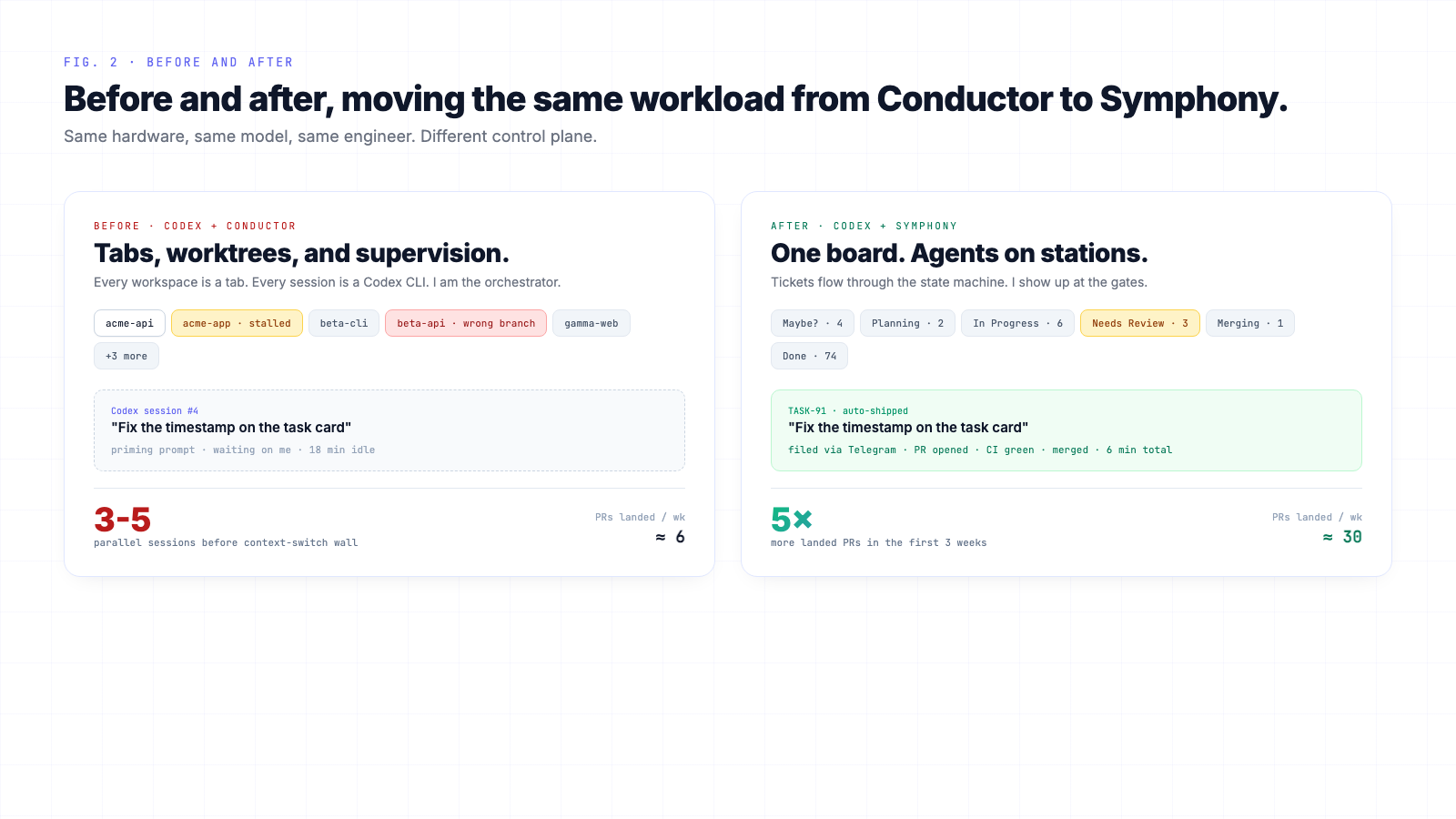
As the volume of my consulting work grew, I found a new kind of burden. On a good morning I would open a few Codex sessions inside the Conductor app, assign tasks, review output, steer the agent, and repeat. In practice, I could comfortably manage three to five sessions at a time before context switching became painful. Beyond that, productivity dropped. I would forget which session was doing what, switch tabs to nudge agents back on track, debug long-running tasks that stalled halfway through, and twice in one week I merged the wrong branch into the wrong project.
The agents were fast, but I had a system bottleneck: my own attention. I had effectively built a team of extremely capable junior engineers, then promoted myself to permanent code reviewer with no time to write code of my own. That was not going to scale.
A shift in perspective
I realized I was optimizing the wrong thing. I was orienting my system around Codex sessions and merged PRs, when PRs and sessions are really a means to an end. Software work, for me as much as for any team, is organized around deliverables: issues, tasks, tickets, milestones.
So I asked myself what would happen if I stopped supervising agents directly and instead let them pull work from my task tracker.
That idea became my version of Symphony, a written workflow that functions as a supervisor over the agents instead of asking me to be one.
Turning my task board into an agent orchestrator
My Symphony started with the same simple concept the OpenAI version did: any open task should get picked up and completed by an agent. Instead of managing Codex sessions across tabs in Conductor, I made my issue tracker the control plane.
In this setup, each open ticket maps to a dedicated agent workspace. The orchestrator continuously watches the task board and ensures that every active task has an agent running in the loop until it is done. If an agent crashes or stalls, the orchestrator restarts it. If new work appears, it picks it up and starts organizing it.
I built the workflow around ticket statuses, using my own board as a state machine.
In practice, Symphony decouples work from sessions and from pull requests. Some issues produce multiple PRs across repos. Others are pure investigation or analysis that never touch the codebase at all.
Once work is abstracted this way, tickets can represent much larger units of work.
I regularly use this pattern to orchestrate complex features and infrastructure migrations. For example, I might file a task asking the orchestrator to analyze a client codebase, the relevant docs, and the existing ticket history, then produce an implementation plan. Once I am happy with the plan, the agent generates a tree of tasks, breaking the work into stages and defining dependencies between them.
Agents only start work on tasks that are not blocked, so execution unfolds naturally and optimally in parallel for this DAG, a sequence of execution steps where each step waits on the right predecessor. For example, I once marked a React upgrade as blocked on a Vite migration. As expected, agents started upgrading React only after the Vite migration finished. Agents can also create work themselves. During implementation or review, they often notice improvements that fall outside the scope of the current task, a performance issue, a refactoring opportunity, a better architecture. When that happens, they file a new ticket I can evaluate and schedule later. Many of those follow-up tasks also get picked up by agents. While I oversee the process, the agents stay organized and keep work moving forward.
This way of working dramatically reduces the cognitive cost of kicking off ambiguous work. If the agent gets something wrong, that is still useful information, and the cost to me is near zero. I can cheaply file tickets for the agent to prototype and explore, then throw away the explorations I do not like.
Because the orchestrator runs on a small box that never sleeps, I can add tasks from anywhere and know an agent will pick them up. The most extreme example I have run so far: I sent three significant tasks into my board from the Telegram app on my phone during a road trip, with the laptop closed in the trunk. By the time I checked again at dinner, two of them had merged and one was waiting on my review.
An increase in exploration from working this way
When I watched the effect of working this way, the most obvious change was output. In the first three weeks after I moved my consulting work onto Symphony, I shipped roughly five times more small-to-medium PRs than I had in the three weeks before. OpenAI reported a similar 5x in their post, and I read that number when it came out and assumed it was generous internal accounting. It is not. It tracks. The deeper shift, though, is how I think about work.
When I no longer spend time supervising Codex sessions, the economics of code changes completely. The perceived cost of each change drops because I am no longer investing my own hours in driving the implementation itself.
That changed my behavior. It became trivial to spin up speculative tasks. Try an idea, explore a refactor, test a hypothesis, and only keep the results that look promising. I file three or four exploratory tickets a week now that I never would have started by hand.
It also broadens who can initiate work. My clients can file feature requests directly into my board over email. They do not need to check out a repo or learn anything about how the agent works. They describe what they want and get back a review packet that includes a video walkthrough of the feature working inside the real product.
Symphony also shines on the slow, fragile last mile of landing a PR. The system watches CI, rebases when needed, resolves conflicts, retries flaky checks, and shepherds changes through the pipeline. By the time a ticket reaches the Merging column, I have high confidence the change will land on main without my babysitting.
After moving to Symphony, I delegate more work to agents and spend my own attention on harder, more exploratory tasks.
Progress comes with new, different problems
Operating at this level comes with tradeoffs. When I moved from steering agents interactively in Conductor to assigning them work at the ticket level, I lost the ability to constantly nudge them mid-flight and course-correct when needed. Sometimes the agent produced something that completely missed the mark. That turned out to be useful. Those failures revealed gaps in my system and helped me make it more robust.
Instead of patching the result manually, I added guardrails and skills so the agents could succeed the next time. Over time this led me to add new capabilities to my harness, like running end-to-end tests against a real browser, driving the app through DevTools, and managing smoke checks for the client deployments I oversee. I significantly improved my documentation and clarified what good looks like for each project.
Not every task fits the Symphony style of work. Some problems still require me working directly with an interactive Codex session, especially ambiguous problems or work that requires strong judgment and a feel for the product. In practice, those are usually the most interesting and enjoyable tasks for me to spend time on anyway.
The difference is that Symphony can handle the bulk of routine implementation work. That lets me focus on a single hard problem at a time, instead of constantly context switching between smaller ones.
I also learned that treating agents as rigid nodes in a state machine does not work well. Models get smarter and can solve bigger problems than the box I try to fit them in. My early versions only asked Codex to implement the task. That approach turned out to be too limiting. Codex is perfectly capable of creating multiple PRs as well as reading review feedback and addressing it. So I gave it tools, the gh CLI, skills to read CI logs, the ability to file follow-up tickets, and now I can ask Codex to do more, like closing stale PRs or pulling reports on completed versus abandoned work. Those tasks fall way outside the initial implementation box.
So I eventually moved toward giving agents objectives instead of strict transitions, much like a good manager assigns a goal to a direct report rather than a list of keystrokes. The power of models comes from their ability to reason, so give them tools and context and let them cook.
Using Symphony to build my Symphony
When you open the OpenAI Symphony repository, the first thing you notice is that Symphony is technically just a SPEC.md file, a definition of the problem and the intended solution. Rather than building a complex supervision system from scratch, I read their spec and pointed my own Codex at it.
OpenAI wrote their reference implementation in Elixir, because when code is effectively free, you can finally pick languages for their strengths, in their case Elixir's concurrency story. I am running a patched and slightly extended fork of that same Phoenix reference, not a rewrite. The core idea can be expressed in a simple Markdown document, but the Phoenix implementation OpenAI shipped is good enough that throwing it out to rewrite in another language never made sense to me. I just bent it to fit my setup.
My first version was just a Codex session running in tmux, polling my board and spawning sub-agents for new tasks. It worked, but it was not particularly reliable. The second version lived inside the same repo I do most of my consulting work in, which I had already shaped to be agent-friendly. I had also built a small harness to give agents skills and context for the recurring kinds of work I get hired for, so my Symphony simply connected the pieces.
Once the basic functionality existed, I used Symphony to build Symphony.
When I first demoed the system to a client by sharing the proof-of-work video the orchestrator attached to a ticket on its own, the reaction was overwhelmingly positive. They asked if they could buy the workflow itself. The right answer was no, because Symphony is not a product, it is a pattern. But that was the moment I knew the shape of this was worth writing down.
So I forked the OpenAI Phoenix implementation, patched the parts that did not fit my setup, and kept iterating on the workflow spec from there. Most of my own client repos are Ruby and TypeScript, but the orchestrator itself does not need to speak the same language as the code the agents are writing, so the Phoenix base stayed. To stress-test my version of the spec, I asked Codex to reimplement the same shape in TypeScript, Go, and Python, and I used the divergence between those one-shots to find ambiguities in my own writing. It succeeded in every language.
Through the process, I removed a lot of incidental complexity, like dependencies on specific tracker vendors or proprietary MCP servers. My Symphony no longer depends on any one client's repo or workflow. The core approach became simple:
For every open task, guarantee that an agent is running in its own workspace.
Beyond the active work, the development workflow itself is now something agents know and follow. The development workflow, work on an issue, check out the right branch, mark it in progress so the human stakeholders know it is being worked on, push the PR, move it to Review, attach the proof video, was a process I used to follow by hand and never wrote down. Now it lives in a small WORKFLOW.md, and Symphony guides the agents through every step. If I decide that agents should also attach a short self-reflection to finished work, I add that line to WORKFLOW.md and the next ticket gets the new behavior.
I also use Codex in its headless app-server mode, a built-in mode for Codex that lets me run it programmatically over a JSON-RPC API for things like starting a thread or reacting to turn events. That is far more convenient and scalable than trying to drive Codex through the CLI or a live tmux session.
The headless mode was a perfect fit for what I was doing. I get to take advantage of the harness Codex provides while keeping all the knobs and hooks I need on my side. For example, to avoid exposing my tracker access tokens to sub-agents, I expose only a narrow function that runs whitelisted requests on their behalf, without leaking the raw credential into the agent's environment.
What's next
Symphony is an intentionally minimal orchestration layer. OpenAI open-sourced it to demonstrate the power of pairing Codex with an everyday workflow tool. I treat my own version the same way. It is not a product I am selling. Think of the OpenAI spec and my patched Phoenix fork as reference implementations. The same way many developers pointed their coding agents at OpenAI's harness engineering post to scaffold their own repos, you can point your favorite coding agent at the Symphony spec and the GitHub repo and build your own version tailored to your environment.
The power comes from Codex itself. Symphony was a way to connect Codex to the board I already used, to solve the work management problem. As coding agents get better at reasoning and following instructions, I suspect the bottleneck inside other businesses will shift from writing code toward managing agentic work, too. The exciting part is that the barrier to experimenting with these systems is now surprisingly low. You can just build things with Codex.